网工进阶必看
48小时系统班试听入口


网工进阶必看
在实践中,丢包一般是当网络变得拥塞时由于路由器缓存溢出引起的。分组重传因此作为网络拥塞的征兆(某个特定的运输层报文段的丢失)来对待,但是却无法处理导致网络拥塞的原因,因为有太多的源以过高的速率发送数据。为了处理网络拥塞原因,需要一些机制以在面临网络拥塞时遏制发送方。
情况1:两个发送方和一台具有无穷大缓存的路由器
甚至在这种(极端)理想化的情况中,已经发现了拥塞网络的一种代价,即当分组的到达速率接近链路容量时,分组经历巨大的排队时延。
情况2:两个发送方和一台具有有限缓存的路由器
另一种网络拥塞的代价,即发送方必须执行重传以补偿因为缓存溢出而丢弃(丢失)的分组。
另一种网络拥塞的代价,即发送方在遇到大时延时所进行的不必要重传会引起路由器利用其链路带宽来转发不必要的分组副本。
情况3:4个发送方和具有有限缓存的多台路由器及多跳路径
由于拥塞而丢弃分组的另一种代价,即当一个分组沿一条路径被丢弃时,每个上游路由器用于转发该分组到丢弃该分组而使用的传输容量最终被浪费掉了。
TCP拥塞控制方法在下节讲解,这里,指出在实践中所采用的两种主要拥塞控制方法,讨论特定的网络体系结构和具体使用这些方法的拥塞控制协议。
在最为宽泛的级别上,可根据网络层是否为运输层拥塞控制提供了显式帮助,来区分拥塞控制方法。
端到端拥塞控制1.在端到端拥塞控制方法中,网络层没有为运输层拥塞控制提供显式支持。即使网络中存在拥塞,端系统也必须通过对网络行为的观察(如分组丢失与时延)来推断之。TCP采用端到端的方法解决拥塞控制,因为IP层不会向端系统提供有关网络拥塞的反馈信息。
1.TCP报文段的丢失(通过超时或3次冗余确认而得知)被认为是网络拥塞的一个迹象,TCP会相应地减小其窗口长度。还有一些关于TCP拥塞控制的最新建议,即使用增加的往返时延值作为网络拥塞程度增加的指示。
网络辅助的拥塞控制1.在网络辅助的拥塞控制中,路由器向发送方提供关于网络中拥塞状态的显式反馈信息。这种反馈可以简单地用一个比特来指示链路中的拥塞情况。如在 ATM可用比特率(Available Bite Rate,ABR)拥塞控制中,路由器显式地通知发送方它(路由器)能在输出链路上支持的最大主机发送速率。
2.默认因特网版本的IP和TCP采用端到端拥塞控制方法。然而,最近IP和TCP也能够选择性地实现网络辅助拥塞控制。
3. 对于网络辅助的拥塞控制,拥塞信息从网络反馈到发送方通常有两种方式,如下图所示:
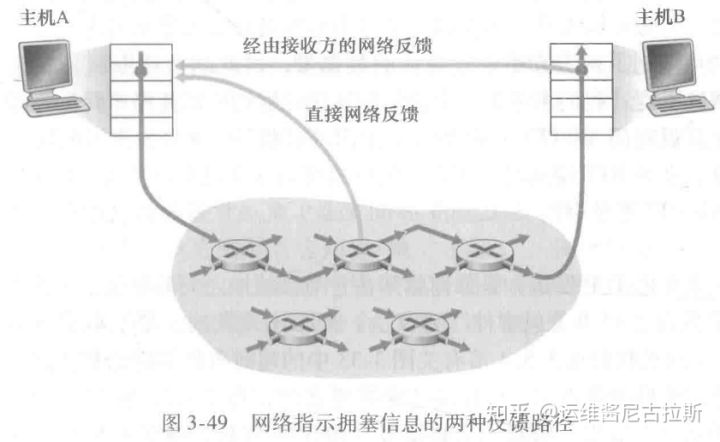
直接反馈信息可以由网络路由器发给发送方。这种方式的通知通常采用了一种 阻塞分组(choke packet)的形式(主要是说:“我阻塞了!”)。
更为通用的第二种形式的通知是,路由器标记或更新从发送方流向接收方的分组中的某个字段来指示拥塞的产生。一旦收到一个标记的分组后,接收方就会向发送方通知该网络阻塞指示。注意到后一种形式的通知至少要经过一个完整的往返时间。
TCP为运行在不同主机上的两个进程之间提供了可靠数据传输服务。
TCP的另一个关键部分就是其拥塞控制机制。
TCP必须使用端到端拥塞控制而不是网络辅助的拥塞控制,因为IP层不向端系统提供显式的网络拥塞反馈。
TCP所采用的方法是让每一个发送方根据所感知到的网络拥塞程度来限制其能向连接发送流量的速率。如果一个TCP发送方感知从它到目的地之间的路径上没什么拥塞,则TCP发送方增加其发送速率;如果发送方感知沿着该路径有拥塞,则发送方就会降低其发送速率。但是这种方法提出了三个问题:
一个TCP发送方如何限制它向其连接发送流量的速率呢?
一个TCP发送方如何感知从它到目的地之间的路径上存在拥塞呢?
当发送方感知到端到端的拥塞时,采用何种算法来改变其发送速率呢?
首先分析一下 TCP 发送方是如何限制向其连接发送流量的。
TCP连接的每一端都是由一个接收缓存、一个发送缓存和几个变量(LastByteRead、rwnd等)组成。运行在发送方的TCP拥塞控制机制跟踪一个额外的变量,即拥塞窗口(congestion window)。拥塞窗口表示为cwnd,它对一个TCP发送方能向网络中发送流量的速率进行了限制。
特别是,在一个发送方中未被确认的数据量不会超cwnd和rwnd中的最小值,即:
LastByteSent − LastByteAcke≤min{cwnd,rwnd} LastByteSent−LastByteAcked≤min\{cwnd,rwnd\}LastByteSent−LastByteAcked≤min{cwnd,rwnd}上面的约束限制了发送方中未被确认的数据量,因此间接地限制了发送方的发送速率。为了理解这一点,考虑一个丢包和发送时延均可忽略不计的连接。因此粗略地讲,在每个往返时间(RTT)的起始点,上面的限制条件允许发送方向该连接发送cwnd个字节的数据,在该RTT结束时发送方接收对数据的确认报文。
因此,该发送方的发送速率大概是cwnd/RTT cwnd/RTTcwnd/RTT字节/秒。通过调节cwnd的值,发送方因此能调整它向连接发送数据的速率。
接下来考虑TCP发送方是如何感知在它与目的地之间的路径上出现了拥塞的。
1.将一个 TCP 发送方的“丢包事件” 定义为:要么出现超时,要么收到来自接收方的 3 个冗余ACK。当出现过度的拥塞时,在沿着这条路径上的一台(或多台)路由器的缓存会溢出,引起一个数据报(包含一个TCP报文段)被丢弃。丢弃的数据报接着会引起发送方的丢包事件(要么超时或收到 3 个冗余ACK),发送方就认为在发送方到接收方的路径上出现了拥塞的指示。
2.考虑了拥塞检测问题后,接下来考虑网络没有拥塞这种更为乐观的情况,即没有出现丢包事件的情况。在此情况下,在TCP的发送方将收到对于以前未确认报文段的确认。TCP将这些确认的到达作为一切正常的指示,即在网络上传输的报文段正被成功地交付给目的地,并使用确认来增加窗口的长度(及其传输速率)。
3.注意到如果确认以相当慢的速率到达(例如,如果该端到端路径具有高时延或包含一段低带宽链路),则该拥塞窗口将以相当慢的速率增加。在另一方面,如果确认以高速率到达,则该拥塞窗口将会更为迅速地增大。因为TCP使用确认来触发(或计时)增大它的拥塞窗口长度,TCP被说成是自计时(self-clocking)的。
TCP 发送方怎样确定它应当发送的速率?
1.给定调节 cwnd 值以控制发送速率的机制,关键的问题依然存在:TCP发送方怎样确定它应当发送的速率呢?如果众多 TCP 发送方总体上发送太快,它们能够拥塞网络,导致拥塞崩溃。然而,如果TCP发送方过于谨慎,发送太慢,它们不能充分利用网络的带宽;
2.这就是说,TCP发送方能够以更高的速率发送而不会使网络拥塞。那么 TCP 发送方如何确定它们的发送速率,既使得网络不会拥塞,与此同时又能充分利用所有可用的带宽?TCP发送方是显式地协作,或存在一种分布式方法使 TCP 发送方能够仅基于本地信息设置它们的发送速率?
TCP使用下列指导性原则回答这些问题:
1.一个丢失的报文段表意味着拥塞,因此当丢失报文段时应当降低 TCP 发送方的速率。
对于给定报文段,一个超时事件或四个确认(一个初始ACK和其后的三个冗余ACK)被解释为跟随该四个 ACK 的报文段的“丢包事件” 的一种隐含的指示。从拥塞控制的观点看,该问题是 TCP 发送方应当如何减小它的拥塞窗口长度,即减小其发送速率,以应对这种推测的丢包事件。
2.一个确认报文段指示该网络正在向接收方交付发送方的报文段,因此,当对先前未确认报文段的确认到达时,能够增加发送方的速率。
确认的到达被认为是一切顺利的隐含指示,即报文段正从发送方成功地交付给接收方,因此该网络不拥塞。拥塞窗口长度因此能够增加。
3.带宽测试。
给定 ACK 指示源到目的地路径无拥塞,而丢包事件指示路径拥塞,TCP调节其传输速率的策略是增加其速率以响应到达的 ACK,除非出现丢包事件,这时才减小传输速率。
因此,为探测拥塞开始出现的速率,TCP发送方增加它的传输速率,从该速率后退,进而再次开始探测,看看拥塞开始速率是否发生了变化。TCP发送方的行为也许类似于要求(并得到)越来越多糖果的孩子,直到最后告知他/她“不行!”,孩子后退一点,然后过一会儿再次开始提出请求。注意到网络中没有明确的拥塞状态指令,即ACK 和丢包事件充当了隐式信号,并且每个 TCP 发送方根据异步与其他 TCP 发送方的本地信息而行动。
该算法包括 3 个主要部分:①慢启动;②拥塞避免;③快速恢复。
其中慢启动和拥塞避免是TCP的强制部分,两者的差异在于对收到的 ACK 做出反应时增加 cwnd 长度的方式。慢启动比拥塞避免能更快地增加cwnd的长度。
快速恢复是推荐部分,对TCP发送方并非是必需的。
①慢启动当一条TCP连接开始时,cwnd的值通常初始置为一个 MSS 的较小值,这就使得初始发送速率大约为 MSS/RTT。(例如MSS = 500字节且RTT = 200ms,则得到的初始发送速率大约只有 20kbps)。
由于对TCP发送方而言,可用带宽可能比 MSS/RTT 大得多,TCP发送方希望迅速找到可用带宽的数量。
因此,在慢启动(slow-start)状态,cwnd的值以 1 个 MSS 开始并且每当传输的报文段首次被确认就增加 1 个 MSS。
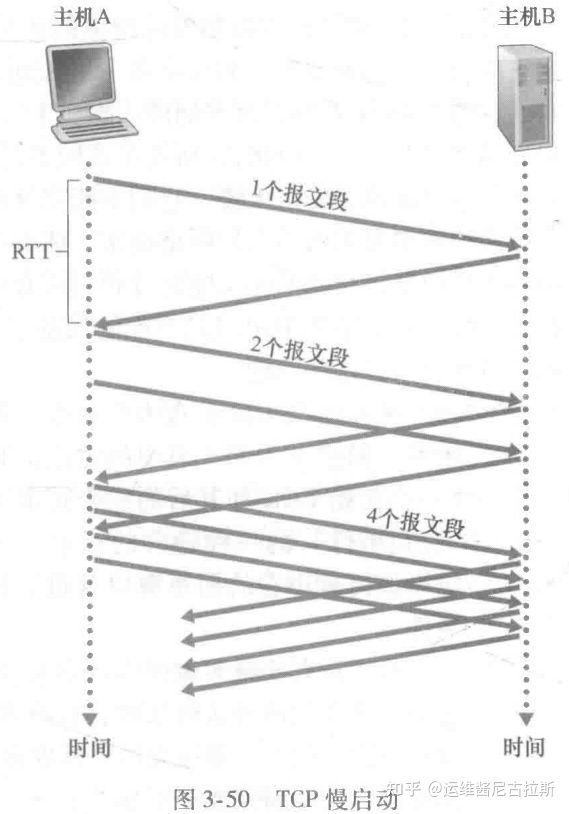
图解:TCP向网络发送第一个报文段并等待一个确认。当该确认到达时,TCP发送方将拥塞窗口增加一个 MSS,并发送出两个最大长度的报文段。这两个报文段被确认,则发送方对每个确认报文段将拥塞窗口增加一个 MSS,使得拥塞窗口变为 4 个MSS,并这样下去。这一过程每过一个 RR,发送速率就翻番。因此,TCP发送速率起始慢,但在慢启动阶段以指数增长。
何时结束这种指数增长呢?慢启动对该问题提供了几种答案:
首先,如果存在一个由超时指示的丢包事件(即拥塞),TCP发送方将cwnd 设置为1并重新开始慢启动过程。它还将第二个状态变量的值ssthresh("慢启动阈值"的速记)设置为cwnd/2,即当检测到拥塞时将 ssthresh 置为拥塞窗口值的一半。
慢启动结束的第二种方式是直接与ssthresh的值相关联。因为当检测到拥塞时ssthresh设为cwnd的值一半,当到达或超过ssthresh的值时,继续使 cwnd 翻番可能有些鲁莽。因此,当 cwnd 的值等于 ssthresh 时,结束慢启动并且 TCP 转移到拥塞避免模式。将会看到,当进入拥塞避免模式时,TCP更为谨慎地增加 cwnd.
最后一种结束慢启动的方式是,如果检测到 3 个冗余ACK,这时 TCP 执行一种快速重传并进入快速恢复状态。
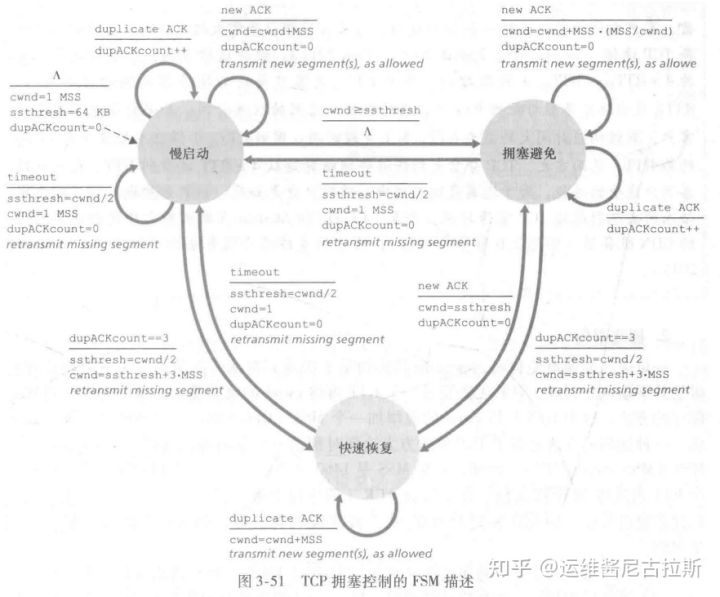
慢启动中的 TCP 行为总结在图3-51中的 TCP 拥塞控制的 FSM 描述中。
②拥塞避免一旦进入拥塞避免状态,cwnd 的值大约是上次遇到拥塞时的一半,即距离拥塞可能并不遥远!因此,TCP无法每过一个 RTT 再将 cwnd 的值翻番,而是采用了一种较为保守的方法,每个 RTT 只将 cwnd 的值增加一个 MSS。这能够以几种方式完成:
一种通用的方法是对于TCP发送方无论何时到达一个新的确认,就将cwnd增加一个 MSS(MSS/cwnd)字节。(例,如果MSS是1460字节且cwnd是14600字节,则在一个 RTT 内发送 10 个报文段。每个到达ACK(假定每个报文段一个ACK)增加 1/10MSS的拥塞窗口长度,因此在收到对所有 10 个报文段的确认后,拥塞窗口的值增加了一个 MSS。
何时应当结束拥塞避免的线性增长呢(每 RTT 1MSS)?
当出现超时时, TCP的拥塞避免算法行为相同。与慢启动的情况一样, cwnd 的值被设为 1 个MSS,当丢包事件出现时,ssthresh 的值被更新为 cwnd 值的一半。
当丢包事件是由一个 3 个冗余ACK事件触发时,网络继续向发送方向接收方交付报文段(就像由收到冗余ACK所指示的那样)。因此,TCP对于这种丢包事件的行为,相比于超时指示的丢包,应当不那么剧烈:TCP将cwnd的值减半(为使测量结果更好,计及已收到的3个冗余的ACK要加上3个MSS),并且当收到3个冗余的ACK,将ssthresh的值记录为cwnd的值的一半。接下来接入快速恢复状态。
③快速恢复在快速恢复中,对于引起 TCP 进入快速恢复状态的缺失报文段,对收到的每个冗余的ACK,cwnd 的值增加一个 MSS。
最终,当对丢失报文段的一个 ACK 到达时,TCP 在降低 cwnd 后进入拥塞避免状态。
如果出现超时事件,快速恢复在执行如同在慢启动和拥塞避免中相同的动作后,迁移到慢启动状态:当丢包事件出现时,cwnd的值被设置为1个MSS,并且ssthresh的值设置为cwnd值的一半。
快速恢复是 TCP 推荐的而非必须的构件。有趣的是,一种称为 TCP Tahoe 的 TCP 早期版本,不管是发生超时指示的丢包事件,还是发生 3个冗余ACK指示的丢包事件,都无条件地将其拥塞窗口减至 1 个MSS,并进入慢启动阶段。TCP的较新版本 TCP Reno,则综合了快速恢复。
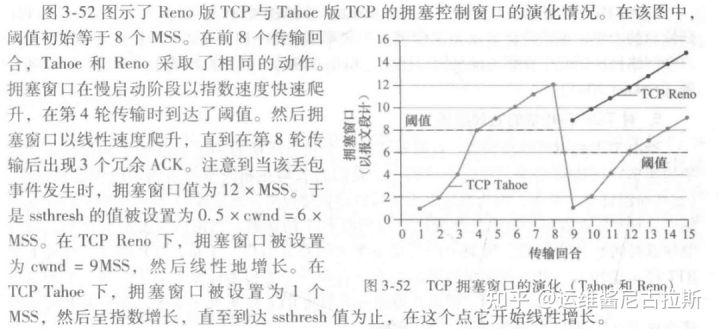
回顾忽略一条连接开始时初始的慢启动阶段,假定丢包由 3 个冗余的ACK而不是超时指示,TCP 的拥塞控制是:每个 RTT 内 cwnd 线性(加性)增加 1 MSS,然后出现 3 个冗余 ACK 事件时 cwnd 减半(乘性减)。因此,TCP 拥塞控制常常被称为加性增、乘性拥塞控制方式。
AMID 拥塞控制引发了在图3-53中所示的“锯齿”行为:
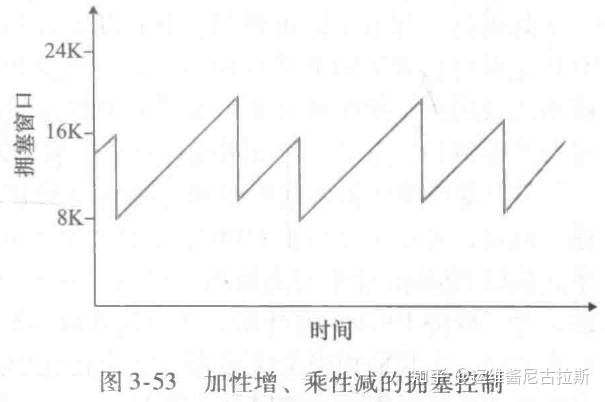
这也很好地图示了前面TCP检测带宽时的直觉,即TCP线性地增加它的拥塞窗口长度(因此增加其传输速率),直到出现3个冗余ACK事件。然后以2个因子来减少它的拥塞窗口长度,然后又开始了线性增长,探测是否还有另外的可用带宽。
如前所述,许多TCP实现采用了 Reno 算法。Reno算法的许多变种已被提出。TCP Vegas 算法试图在维持较好的吞吐量的同时避免拥塞。Vegas 的基本思想是:①在分组丢失发生之前,在源与目的地之间检测路由器中的拥塞;②当检测出快要发生的分组丢失时,线性地降低发送速率。快要发生的分组丢失时通过观察 RTT 来预测的。分组的 RTT 越长,路由器中的拥塞越严重。
到2015年年底,TCP 的Ubuntu Linux 实现默认提供了慢启动、拥塞避免、快速恢复、快速重传和 SACK,也提供了诸如 TCP Vegas 和 BIC 等其他拥塞控制算法。
推荐阅读 :
>>>【必备干货】网工入门必会桥接教程,外网+GNS3+Vmware
网工界市场认可度极高的华为认证,你考了吗?
拿下华为HCIE认证之后,你可以:
跨越90%企业的招聘硬门槛
增加70%就业机会
拿下BAT全国TOP100大厂敲门砖
体系化得到网络技术硬实力
技术大佬年薪可达30w+

