Linux必备技能
48小时系统班试听入口


Linux必备技能

容器编排系统需要满足的条件:1.服务注册,服务发现。2.负载均衡。3.配置、存储管理。4.健康检查。5.自动扩缩容。6.零宕机。
Kubernetes采用主从分布式架构,包括Master(主节点)、Worker(从节点或工作节点),以及客户端命令行工具kubectl和其它附加项。

1、K8S Master节点
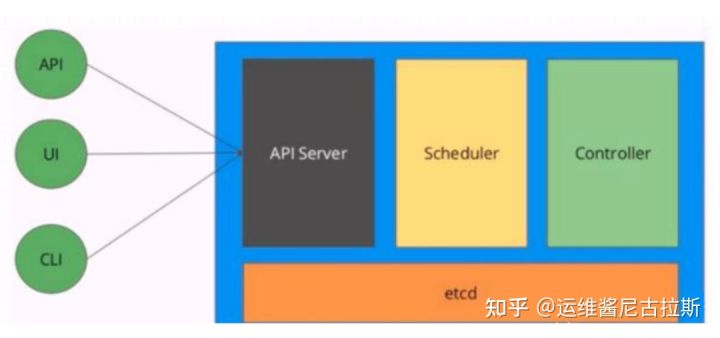
2、K8S Node节点
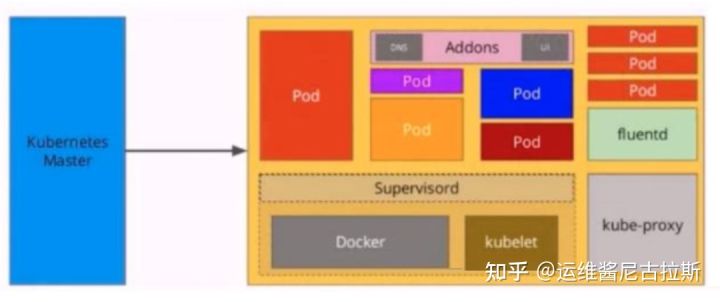
###Master组件###--kube-apiserver-- 用户暴露kubernetes API,任何资源请求或调用操作都是通过 kube-apiserver 提供的接口进行。 以HTTP Restful API 提供接口服务,所有对象资源的增删改查和监听操作都交给API Server处理后再提交给 Etcd存储。 可以理解成API server 是 k8s 的请求入口服务。API Server负责接受k8s所有请求(来自 ui界面或者 CTL 命令行工具), 然后根据用户的具体请求,去通知其他组件干活。可以说API server是k8s集群架构的大脑。 --Kube-controller-manager-- 运行管理控制器,是k8s集群中处理常规任务的后台线程,是k8s及群里所有资源对象的自动化控制中心。 在k8s集群中,一个资源对应一个控制器,而Controller manager就是负责管理这些控制器的。 由一系列控制器组成,通过API Server 监控整个集群的状态,并确保集群处于预期的工作状态,比如当某个Node意外宕机,controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。 这些控制器主要包括: Node Controller (节点控制器):负责在节点出现故障时发现和响应。 Replocation Contreller(副本控制器):负责保证集群中一个RC(资源对象 Replication Controller)所关联的 pod 副本数始终保持预设值。可以理解成确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。 Endpoints Controller (端点控制器):填充端点对象(即连接Services 和 Pods),负责监听Service和对应的Pod副本的变化。 可以理解端点是一个服务暴露出来的访问点,如果需要访问一个服务,则必须在知道它的 endpoint。 Service Accouni & Token Controllers (服务账户和令牌控制器):为新的命名空间创建默认账户和API访问令牌。 ResourceQuota Controller (资源配额控制器) :确保指定的资源对象在任何时候都不会超量占用系统物理资源。 Namespace Controller (命名空间控制器):管理namespace的生命周期。 Service Controller (服务控制器):属于k8s集群与外部的云平台之间的一个接口控制器。 --Kube-scheduler--- 是负载资源调度的进程,根据调度算法为新创建的Pod选择一个合适的Node节点。 可以理解成k8s所有Node节点的调度器。当用户要部署服务时,Schheduler 会根据调度算法选择最合适的Node节点来部署Pod。 *预算策略(predicate) *优选策略(priorities) Master工作流程: API Server 接收到请求创建一批 Pod ,API Server 会让 Controller-manager 按照所预设的模板去创建 Pod,Controller-manager 会通过 API Server 去找 Scheduler 为新创建的 Pod 选择最适合的 Node 节点。比如运行这个 Pod 需要 2C4G 的资源,Scheduler 会通过预算策略在所有 Node 节点中挑选最优的。Node 节点中还剩多少资源是通过汇报给 API Server 存储在 etcd 里, API Server 会调用一个算法找到 etcd 里所有 Node 节点的剩余资源,再对比 Pod 所需要的资源,在所有 Node 节点中查找哪些 Node 节点符合要求。 如果都符合,预算策略就交给优选策略处理,优选策略再通过 CPU 的负载、内存的剩余量等因素选择最合适的 Node 节点,并把 Pod 调度到这个 Node 节点上运行。###配置存储中心###eicd k8s 的存储服务。etcd 是分布式键值存储系统,存储了k8s的关键配置和用户配置,k8s中仅API Server 才具备读写权限,其他组件必须通过API Server的接口才能读写数据。###Node组件###kubelet Node 节点的监视器,以及与Master节点的通讯器。Kubelet是Master节点安插在Node 节点上的“眼线”,他会定时向API Server汇报自己 Node节点上运行的服务的状态,并接受来自Master节点的指示采取调整措施。 从Master节点获取自己节点上Pod的期望状态(比如运行什么容器、运行的副本数量,网络或者存储如何配置等),直接跟容器引擎交互实现容器的生命周期管理, 如果自己节点上Pod的状态与期望状态不一致,则调用对应的容器平台接口(即docker的接口)达到这个状态。 管理镜像和容器的清理工作,保证节点上镜像不会占满磁盘空间,退出的容器不会占用太多资源。 kube-Proxy 在每个Node节点上实现pod网络代理,是Kubernetes Service资源的载体,负责维护网络规则和四层均衡负载工作。 负责写入规则至iptables、ipvs实现服务映射访问的。 kube-proxy 本身不是直接给pod提供网络,pod的网络是由kubelet提供的,kube-proxy实际上维护的是虚拟的Pod集群网络。 kube-apiserver 通过监控kube-proxy 进行对kubernetes service的更新和端点的维护。 在k8s集群中微服务的负载均衡是由Kube-proxy实现的。kube-proxy是k8s集群内部的负载均衡器。它是一个分布式负代理服务器,在k8s的每个节点上都会运行一个kube-proxy组件。###Kubernetes核心概念###kubernetes包含多种类型的资源对象:Pod、Label、Service、Replication Controller等。 所有的资源对象都可以通过Kuberbetes提供的kubectl工具进行增删改查等操作,并将其保存在etcd中持久化储存。 kubernetes其实是一个高度自动化的资源控制系统,通过跟踪对比etcd存储里保存的资源期望状态与当前环境中的实际资源状态的差异,来实现自动控制和自动纠错等高级功能。 Pod pod是kubernetes创建或部署的最小最简单的基本单位,一个pod代表集群上正在运行的一个进程。 可以把pod理解成豌豆荚,而同一pod内的每个容器是一颗颗豌豆。 一个pod由一个或多个容器组成,Pod中容器共享网络、存储和计算资源,在同一台Docker主机上运行。 一个pod里可以运行多个容器,又叫便车模式。而在生产环境中一般都是单个容器或者具有强关联互补的多个容器组成一个pod。 同一个pod之间的容器可以通过localhost互相访问,并且可以挂载pod内所有的数据卷;但是不同的pod之间吊人容器不能用localhost访问,也不能挂载其他的pod数据卷。 Pod控制器 pod控制器是pod启动的一种模板,用来保证在k8s里启动的pod应始终按照用户的预期运行(副本数,生命周期,监控状态检查等)。 k8s内提供了众多的pod控制器,常用的有以下几种: Deployment:无状态应用部署。Deployment的作用是管理和控制Pod和Replicaset,管控他们运行在用户期望的状态中。 Replicaset:确保预期的Pod副本数量。Replicaset的作用就是管理和控制Pod,管控他们好好干活。但是,Replicaset受控于Deployment。 Daemonset:确保所有节点运行同一类pod,保证每个节点上都有一个此类pod运行,通常用于实现系统级后台任务。 Statefulset:有状态应用部署 Job:一次性任务。根据用户的设置,Job管理的pod把任务成功完成就自动退出了。 Cronjob:周期性计划任务。 Label选择器 给某个资源对象定义一个Label,就相当于给他打了一个标签;随后可以通过标签选择器(Label selector)查询和筛选拥有某些Label的资源对象。 标签选择器目前有两种:基于等之关系(等于、不等于)和基于几何关系(属于、不属于、存在)。 Service 在k8s的及群里,虽然每个Pod会被分配一个单独的ip地址,但由于pod是有生命周期的(它们可以被创建,而且销毁之后不会在启动),随时可能 会因为业务的变更,导致这个ip地址也会随着Pod的销毁而消失。 service就是用来解决这个问题的核心概念。 k8s中的service并不是我们常说的“服务”的含义,而更像是网关层,可以看作一组提供相同服务的pod的对外访问接口、流量均衡器。 Service作用于哪些pod,是通过标签选择来定义的。 在k8s集群中,Service可以看作一组提供相同服务的Pod的对外访问接口。客户端需要访问的服务就是Service对象。每个Service都有一个固定的虚拟ip(这个ip也被称为Cluster ip), 自动并且动态地绑定后端的pod,所有的网络请求直接访问Service的虚拟ip,Service会自动向后端做转发。 Service除了提供稳地的对外访问方式之外,还能起到负载均衡的功能,自动把请求流量分步到后端所有的服务上,service可以做到对客户透明地进行水平扩展。 而实现service这一功能的关键,就是kube-proxy。kube-proxy运行在每个节点上,监听api service中服务对象的变化。 可通过ipvs来实现网络的转发。 Ingress service 主要负责k8s集群内部的网络拓扑,那么集群外部怎么访问集群内部呢?这个时候就需要Ingress了。 Ingress是整个k8s集群的接入层,负责集群内外通讯。 Ingress是k8s及群里工作在osi网络才考模型下,第7层的应用,对外暴露的接口,典型的访问方式是http/https。 Service只能进行第四层的流量调度,表现形式是ip+port。Ingress则可以调度不同业务域、不同URL访问路径的业务流量。 比如:客户端请求http://www.kgc.com:port ----》Ingress-----》Service -----》 pod Name 由于k8s内部,使用“资源”来定义每一种逻辑概念(功能),所以每种“资源”,都应该有自己的名称。 “资源”有api版本(apiversion)、类别(kind)、元数据(metadata)、定义清单(spec)、状态(status)等配置信息。 “名称”通常定义在“资源”的“元数据”信息里。在同一个namespace空间中必须是唯一的。 Namespace 随着项目增多,人员增加,集群规模的扩大,需要一种能够逻辑上隔离k8s内各种“资源”的方法,就是Namespace。 Namespace是为了把一个k8s集群划分为若干个资源不可共享的虚拟集群组而诞生的。 不同Namespace内的“资源”名称可以相同,相同Namespace内的同种“资源”名称不能相同。 合理的使用k8s的Namespace,可以使得集群管理员能够更好的对交付到k8s里的服务进行分类管理和浏览。 K8s里默认存在的Namespace有:default、kube-system、kube-public等。 查询k8s里特定“资源”要带上相应的Namespace。
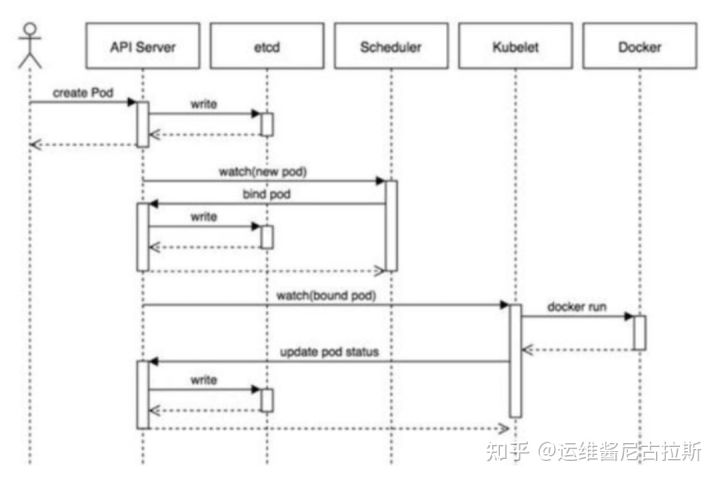 POD创建时序图
POD创建时序图
1、用户提交创建POD请求。
2、API Server 处理用户请求,存储Pod数据到Etcd。
3、Schedule通过和 API Server的监听机制,查看到新的pod,尝试为Pod绑定Node。
4、过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机。
5、主机打分:对第一步筛选出的符合要求的主机进行打分,在此阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
6、选择主机:选择得分最高的主机,进行binding操作,结果存储到Etcd中。
7、kubelet根据调度结果执行Pod创建操作:绑定成功后,会启动container, Docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
8、POD创建完成。
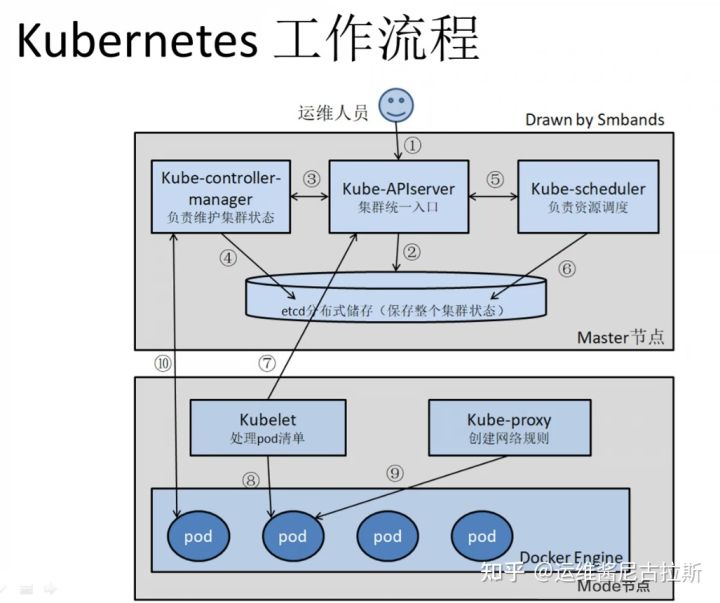
工作流程:
1.运维人员向kube-apiserver发出指令(我想干什么,我期望事情是什么状态)
2.api响应命令,通过一系列认证授权,把pod数据存储到etcd,创建deployment资源并初始化。(期望状态)
3.controller通过list-watch机制,监测发现新的deployment,将该资源加入到内部工作队列,发现该资源没有关联的pod和replicaset,启用deployment controller创建replicaset资源,再启用replicaset controller创建pod。
4.所有controller被创建完成后.将deployment,replicaset,pod资源更新存储到etcd。
5.scheduler通过list-watch机制,监测发现新的pod,经过主机过滤、主机打分规则,将pod绑定(binding)到合适的主机。
6.将绑定结果存储到etcd。
7.kubelet每隔 20s(可以自定义)向apiserver通过NodeName 获取自身Node上所要运行的pod清单.通过与自己的内部缓存进行比较,新增加pod。
8.kubelet创建pod。
9.kube-proxy为新创建的pod注册动态DNS到CoreOS。给pod的service添加iptables/ipvs规则,用于服务发现和负载均衡。
10.controller通过control loop(控制循环)将当前pod状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller会将pod修改为用户期望状态,实在不行会将此pod删掉,然后重新创建pod。

推荐阅读
>>>新手必备-Linux系统安装配置+Xshell远程连接
运维界升职加薪必备的云计算技术,你学了吗?
学完高级运维云计算课程之后,你可以:
跨越90%企业的招聘硬门槛
增加70%就业机会
拿下BAT全国TOP100大厂敲门砖
体系化得到运维技术硬实力
技术大佬年薪可达30w+